随着 AI 的应用变广,各类 AI 程序已逐渐普及。AI 已逐渐深入到人们的工作生活方方面面。而 AI 涉及的行业也越来越多,从最初的写作,到医疗教育,再到现在的音乐。 Suno 是一个专业高质量的 AI 歌曲和音乐创作平台,用户只需输入简单的文本提示词,即可根据流派风格和歌词生成带有人声的歌曲。该 AI 音乐生成器由来自 Meta、TikTok、Kensho 等知名科技公司的团队成员开发,目标是不需要任何乐器工具,让所有人都可以创造美妙的音乐。 以下是模型更新的进度:Documentation Index
Fetch the complete documentation index at: https://docs.acedata.cloud/llms.txt
Use this file to discover all available pages before exploring further.
| 版本 | model | 上线时间 | lyric 限制 | style 限制 | 歌曲最长时长 |
|---|---|---|---|---|---|
| v5 | chirp-v5 | 2025.09.23 | 5000 | 1000 | 8 分钟 |
| v4.5+ | chirp-v4-5-plus | 2025.07.17 | 5000 | 1000 | 8 分钟 |
| v4.5 | chirp-v4-5 | 2025.05.03 | 5000 | 1000 | 4 分钟 |
| v4 | chirp-v4 | 2024.12.17 | 3000 | 200 | 150 秒 |
| v3.5 | chirp-v3-5 | --- | 3000 | 200 | 120 秒 |
chirp-v5,可生成 9 分钟的歌曲。
然而 Suno 官方是并没有提供 API 的,AceDataCloud 提供了一套 Suno 的 API,模拟对接了 Suno 官方,可以方便快捷地生成想要的音乐。
申请和使用
要使用 Suno Audios API,首先可以到 Suno Audios Generation API 页面点击「Acquire」按钮,获取请求所需要的凭证: 如果你尚未登录或注册,会自动跳转到登录页面邀请您来注册和登录,登录注册之后会自动返回当前页面。
在首次申请时会有免费额度赠送,可以免费使用该 API。
如果你尚未登录或注册,会自动跳转到登录页面邀请您来注册和登录,登录注册之后会自动返回当前页面。
在首次申请时会有免费额度赠送,可以免费使用该 API。
基本使用
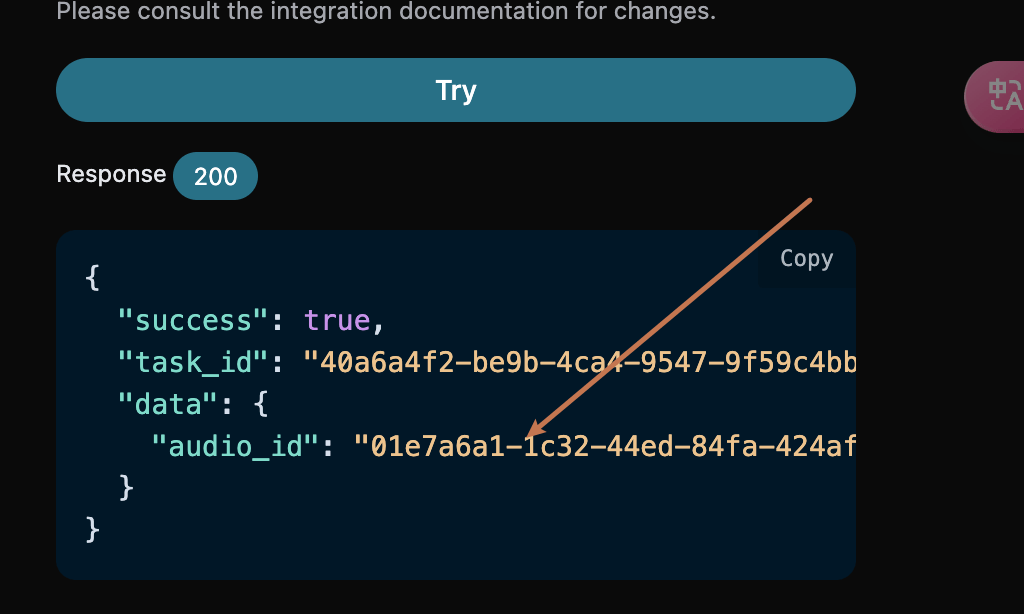
想些什么歌曲,可以任意输入一段文字,比如我想生成一个关于圣诞的歌曲,就可以输入a song for Christmas,如图所示:
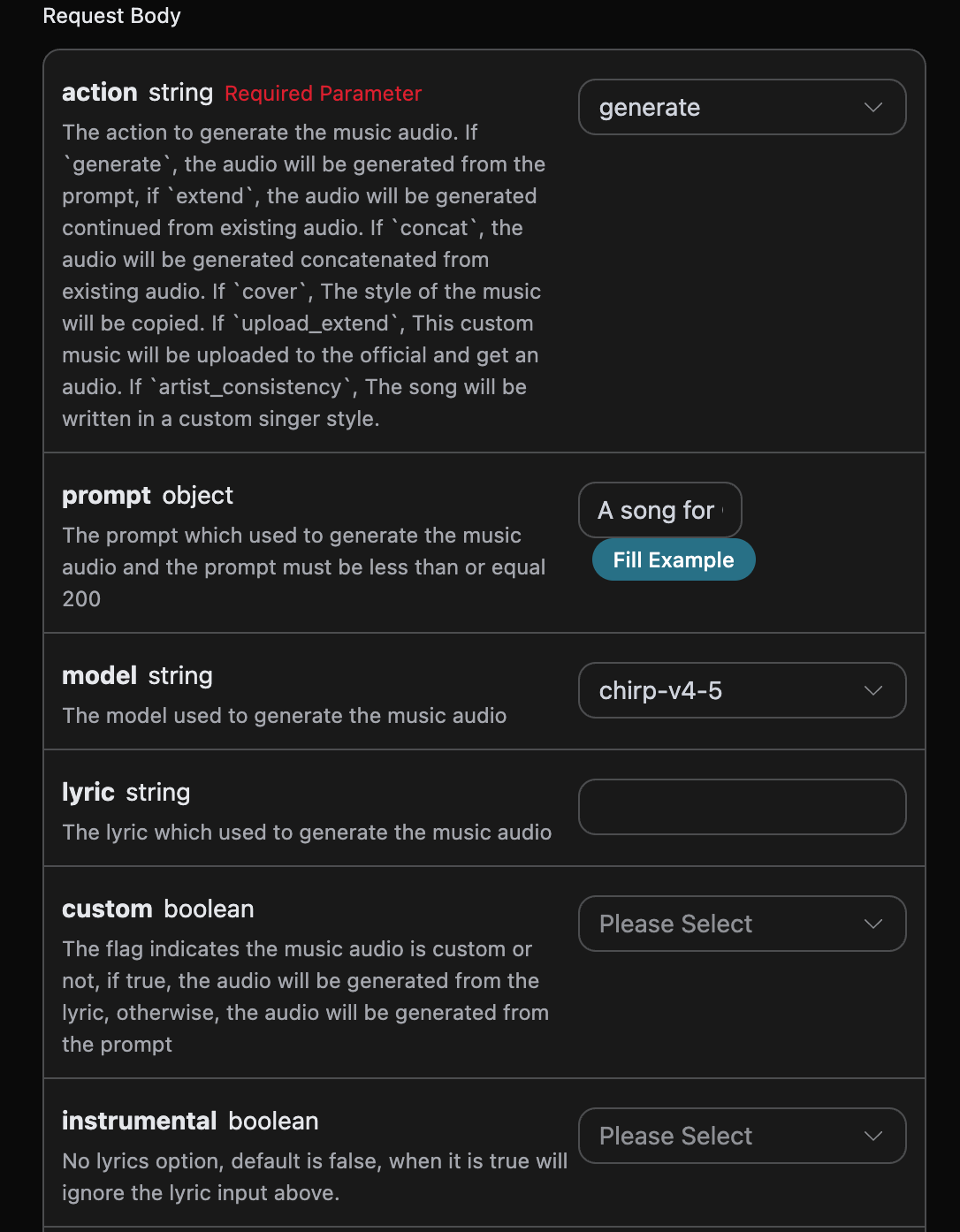
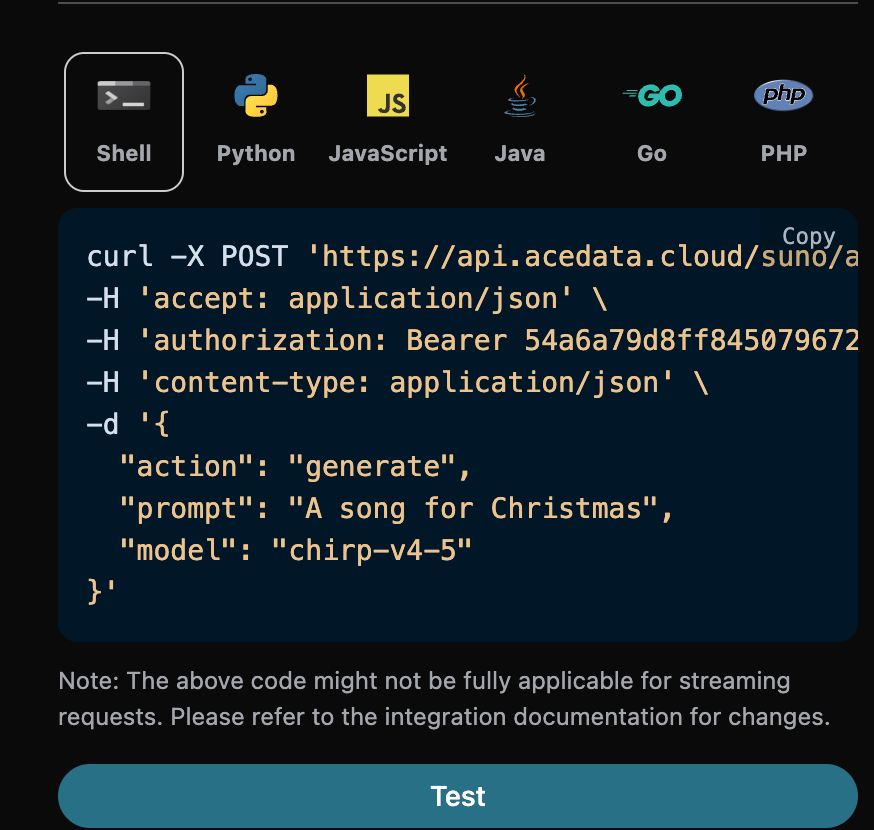
accept:想要接收怎样格式的响应结果,这里填写为application/json,即 JSON 格式。authorization:调用 API 的密钥,申请之后可以直接下拉选择。
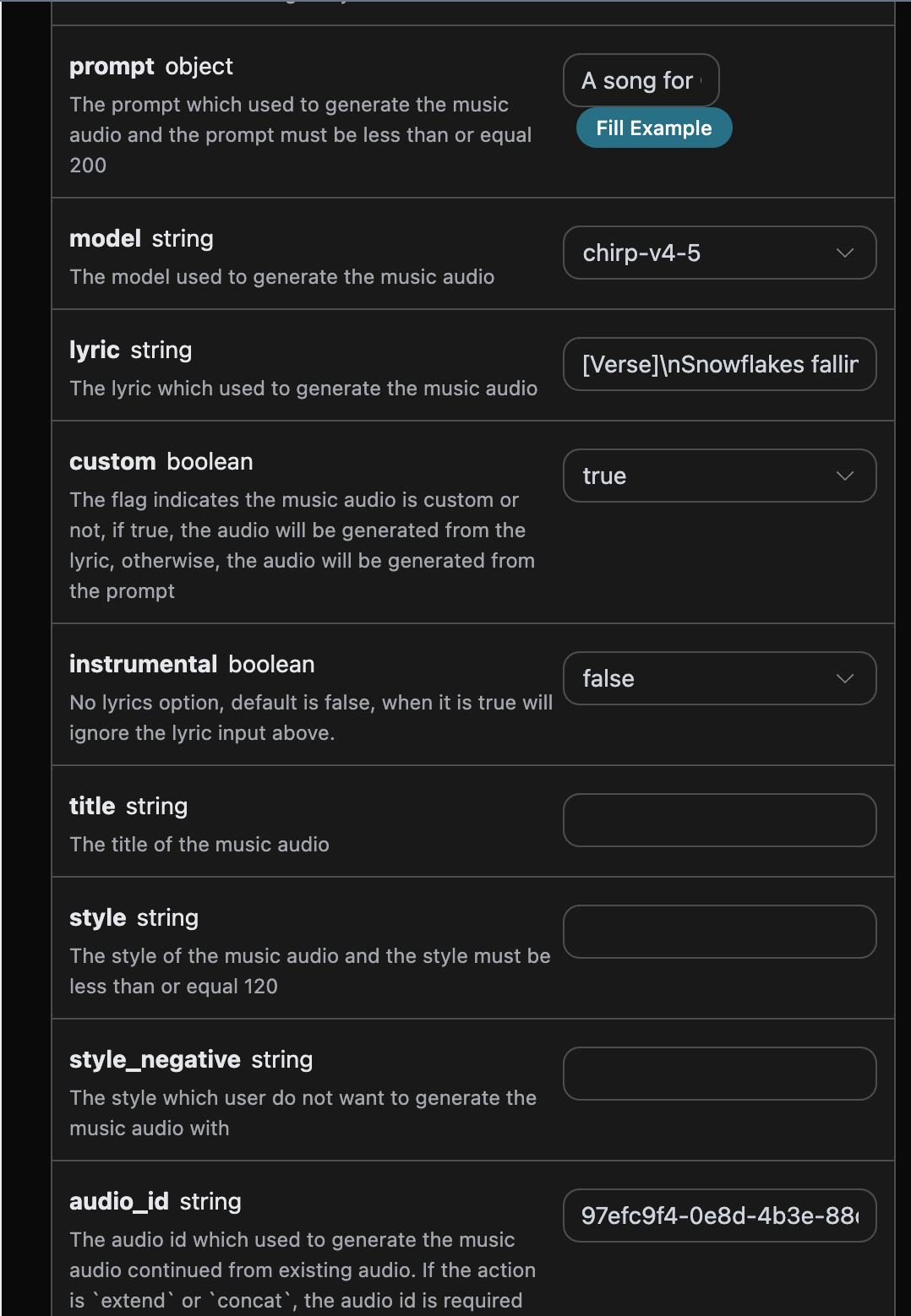
action:此次音乐生成任务的行为,默认是generate,主要包含:extend、upload_extend、cover、upload_cover、replace_section、replace_section、concat、stems、all_stems、remaster。prompt:Suno 官方的灵感模式的提示词。model:此次音乐生成任务的模型,默认是chirp-v3-5,主要包含:chirp-v3、chirp-v4、chirp-v3-5、chirp-v4-5、chirp-v4-5-plus、chirp-v5。lyric:Suno 官方的自定义模式的歌词内容。custom:是否采用自定义模式,默认是:false。instrumental:Suno 官方的灵感模式的纯音乐选项。title:Suno 官方的自定义模式的音乐标题。style:Suno 官方的自定义模式的音乐风格。style_negative:Suno 官方的自定义模式的排除风格。audio_weight:上传的参考音频占比,范围 0-1,越大越依赖参考音频。audio_id:参考音乐的 ID。overpainting_start/overpainting_end:为已有纯音乐补充人声的起止时间,单位秒。underpainting_start/underpainting_end:为清唱加伴奏的起止时间,单位秒。persona_id:艺术家的歌曲 ID。continue_at:以秒为单位继续现有音频的时间。例如,213.5 表示继续到 3 分 33.5 秒。style_influence:style_influence高级参数。replace_section_end:替换片段的最终时间。replace_section_start:替换片段的起始时间。vocal_gender:控制男女声,女声f,男声m,4.5 及以上模型有效。weirdness:weirdness高级参数。lyric_prompt:生成歌词的 prompt,当且仅当custom为true并且lyric没有传的时候生效。callback_url:需要回调结果的 URL。
- success:生成是否成功,如果成功则为
true,否则为false - data:是一个列表,包含了生成的歌曲的详细信息。
- state: 歌曲生成状态,主要包含四种,具体的如下:
- succeeded:生成成功
- pending:队列中
- running:执行中
- error:失败
- id:歌曲 ID
- title:歌曲的标题
- image_url:歌曲的封面图片
- lyric:歌曲的歌词
- audio_url:歌曲的音频文件,打开就是一个 mp3 音频。
- video_url:歌曲的视频文件,打开就是一个 mp4 视频。
- created_at:创建的时间
- model:使用的模型,一般是最新的 v3 模型
- style:风格
- state: 歌曲生成状态,主要包含四种,具体的如下:
自定义生成
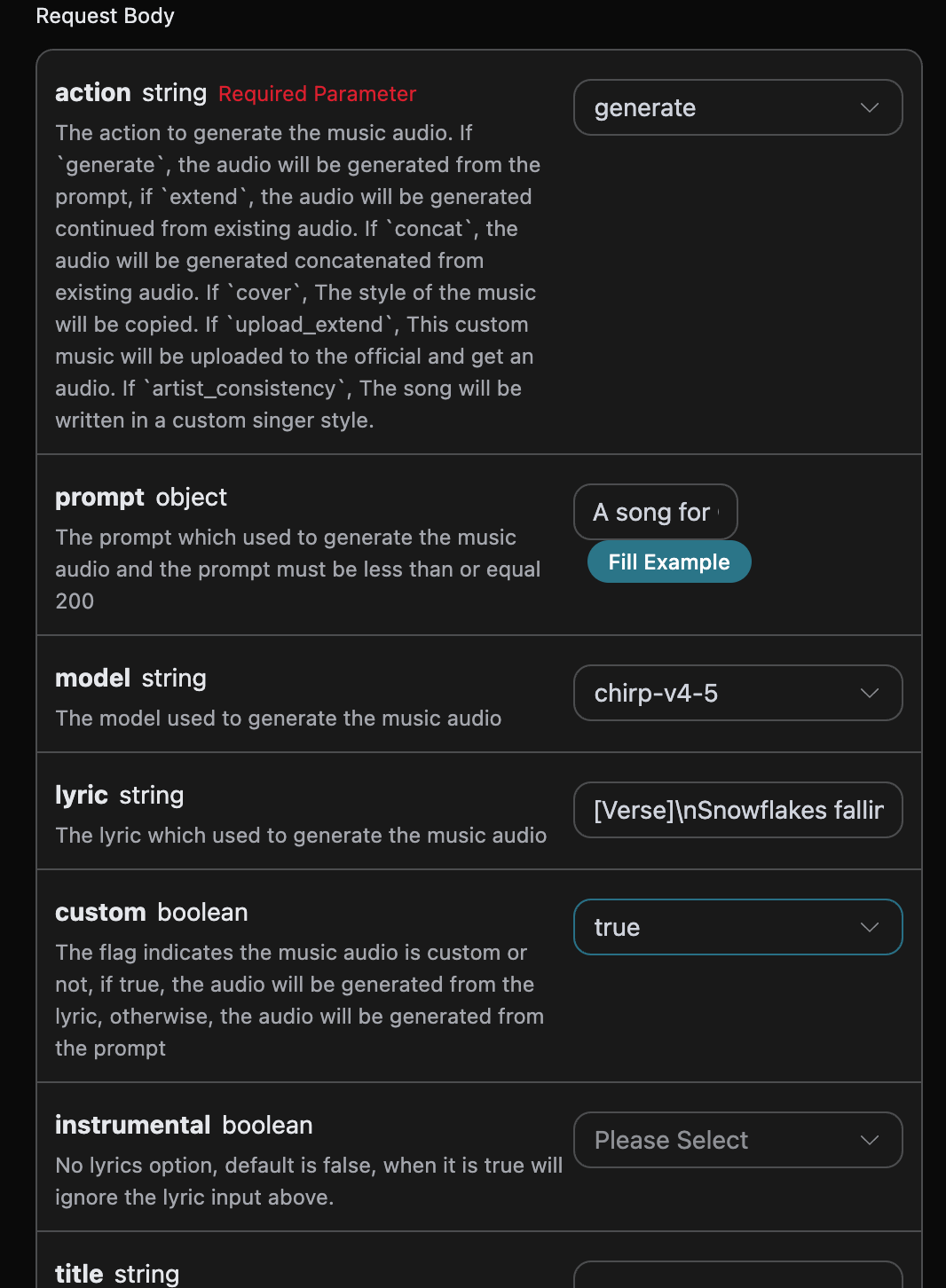
如果想自定义生成歌词,可以输入歌词: 这时候lyric 字段可以传入类似如下内容:
注意,这里的歌词中 \n 是换行符,如果你不知道如何生成歌词,可以使用 AceDataCloud 提供的歌词生成 API 来通过 prompt 生成歌词,API 是 Suno Lyrics Generation API。
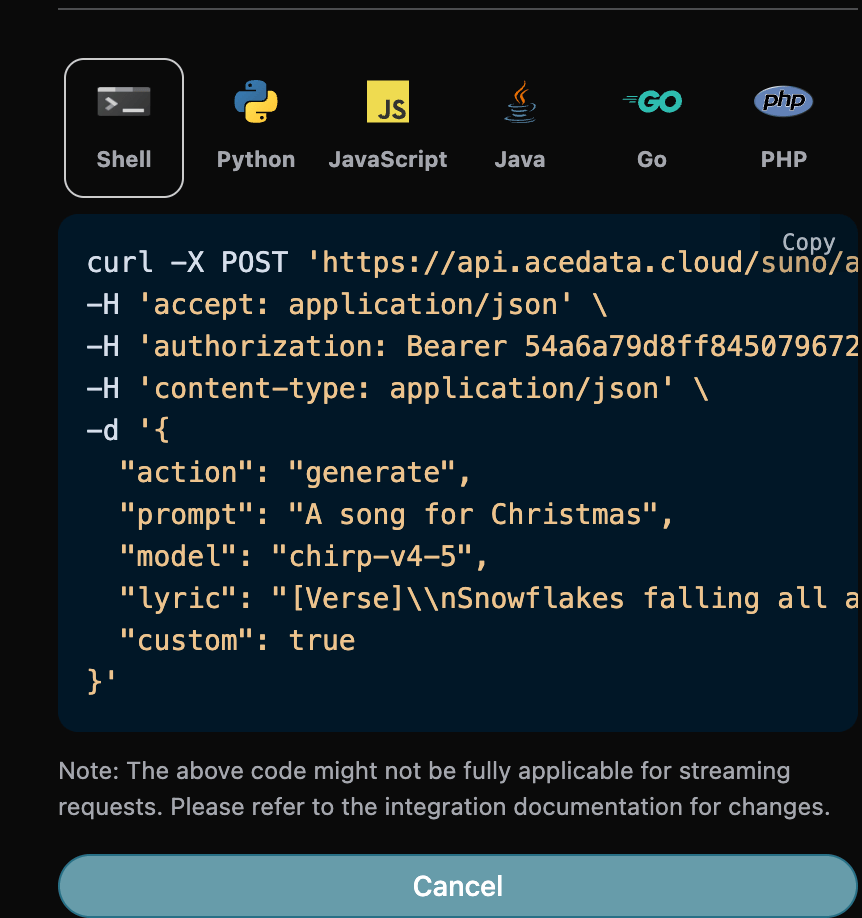
接下来我们要根据歌词、标题、风格自定义生成歌曲,就可以指定如下内容:
- lyric:歌词文本
- custom:填写为
true,代表自定义生成,该参数默认为 false,代表使用prompt生成。 - title:歌曲的标题。
- style:歌曲的风格,选填。
自定义歌手风格生成功能
如果想使用歌手风格来生成歌曲的话,首先通过上文的基本使用生成一首歌曲, 最后得到了需要设置这个歌曲为歌手风格,然后需要进入Suno Persona API根据官方生成的音乐 IDaudio_id 来生成一个歌手风格的 id 参数 persona_id,具体的参数如下图所示:
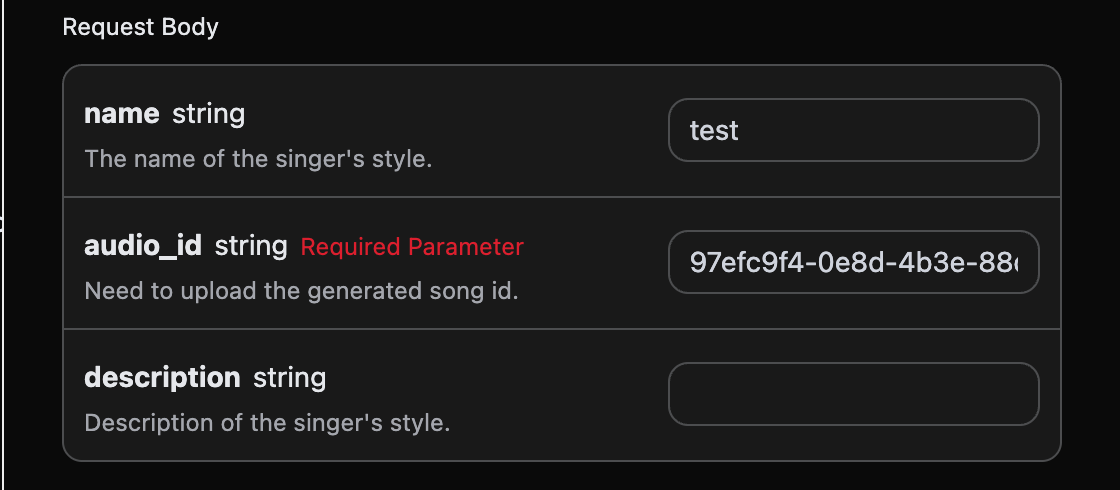
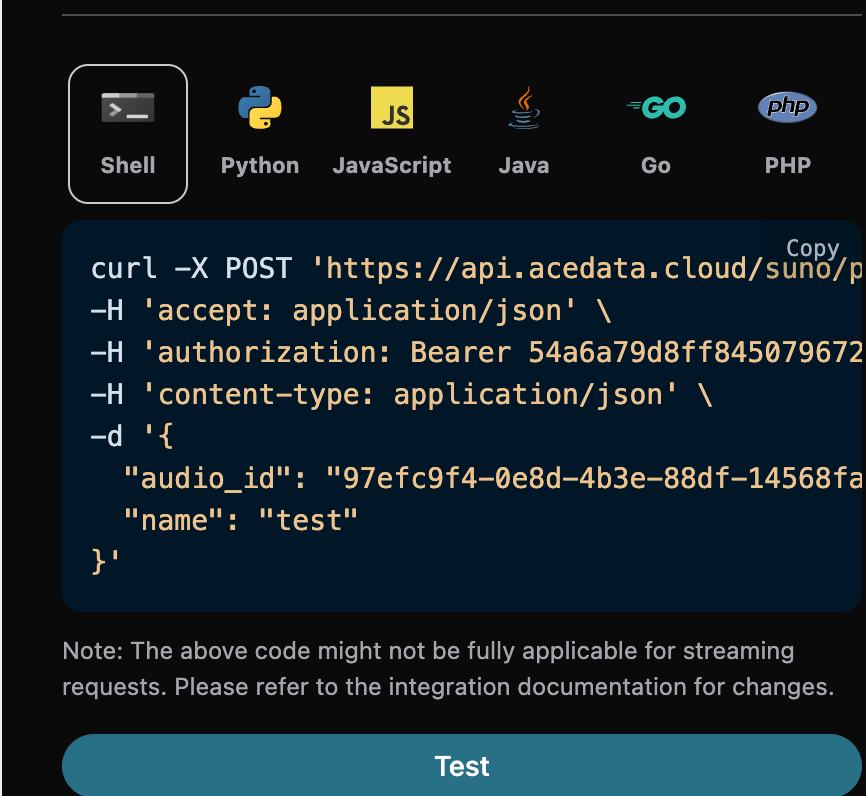
audio_id 和 persona_id 分别为 97efc9f4-0e8d-4b3e-88df-14568fa1b11f、e0d7319e-aa2a-44cb-b00a-916218d7cb0b 为此次的示例数据。 然后可以将参数 action 设置为 artist_consistency (如果是新版的歌手风格Persona-v2-vox,action 必须设置为 artist_consistency_vox),并且输入需要继续生成歌曲的 ID 、 歌手风格 ID,填写样例如下:
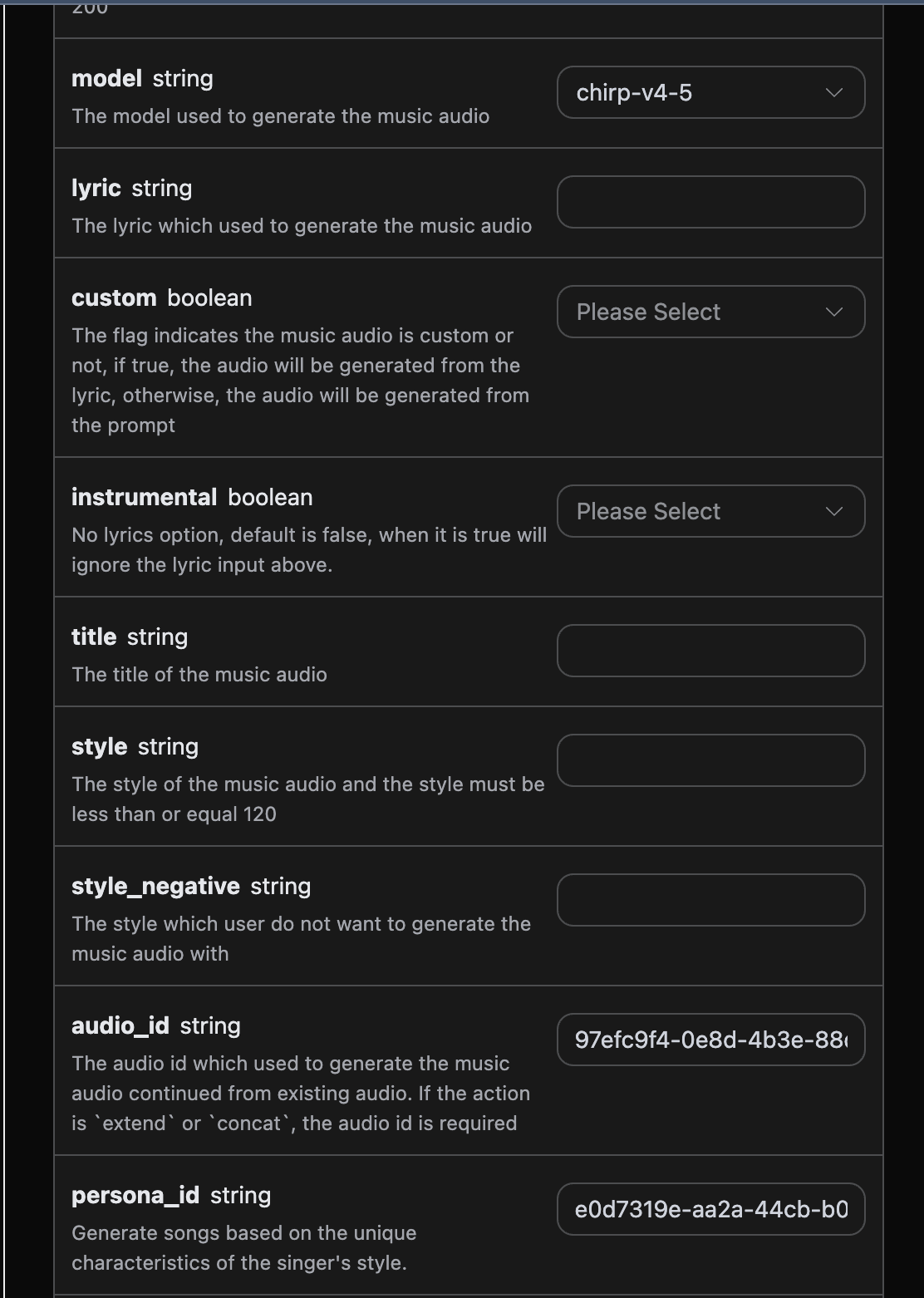
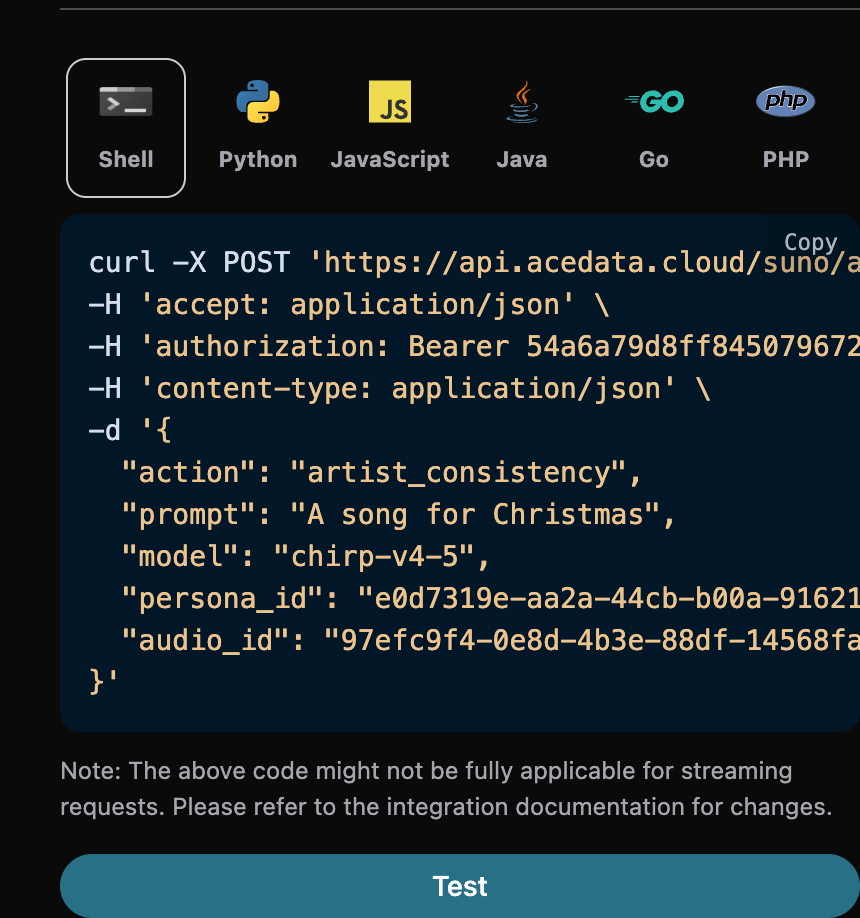
继续生成功能
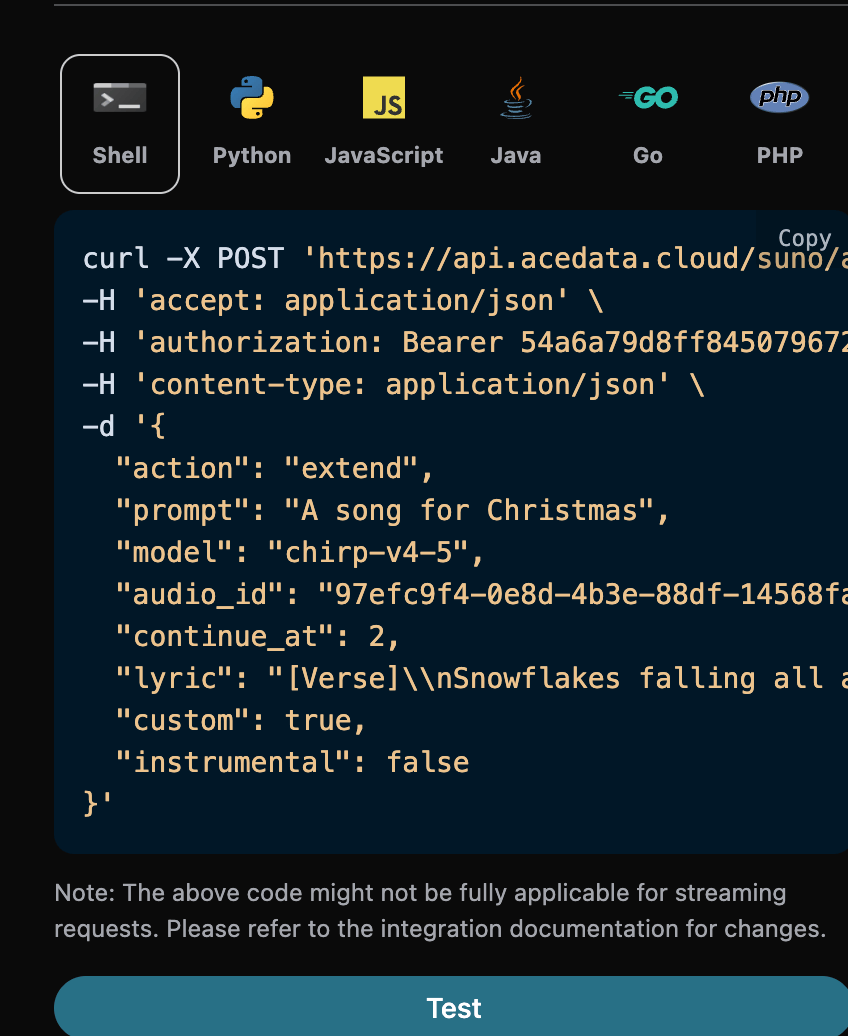
如果想对已经生成的 Suno 歌曲进行继续生成的话,可以将参数action 设置为 extend ,并且输入需要继续生成歌曲的 ID,歌曲 ID 的获取是根据基本使用来获取,通过上文可知,这时候可以看到歌曲的 ID 为:
注意,这里的歌词中 id 是生成后歌曲的 ID,如果你不知道如何生成歌曲,可以参考上文的基本使用来生成歌曲。
如果想对自己上传的歌曲进行继续生成的话,可以将参数 action 设置为 upload_extend ,并且输入需要继续生成自定义上传的歌曲 ID,歌曲 ID 的获取是使用 Suno Upload Generation API来获取,如下图所示:
- lyric:歌词文本
- custom:填写为
true,代表自定义生成,该参数默认为 false,代表使用prompt生成。 - style:歌曲的风格,选填。
- continue_at:以秒为单位继续现有音频的时间。例如,213.5 表示继续到 3 分 33.5 秒。
获取完整歌曲
当基于原有的歌曲继续生成歌曲之后,返回的歌曲并不包含原来的歌曲内容。如果要获得完整的歌曲内容,需要使用拼接功能,就可以指定如下内容:- action:内容为
concat。 - audio_id:最后一个片段的 ID。
音乐翻版
当基于原有的歌曲继续生成歌曲之后,返回的歌曲的风格可能不太合适。如果要对原先生成的歌曲(若是自定义上传的音乐也支持)进行翻版,需要使用音乐翻版方法,就可以指定如下内容:- action:内容为
cover,当是对自定义上传的音乐进行翻版操作的时候必须指定内容为:upload_cover。 - audio_id:之前生成歌曲的 ID。
替换片段
当生成歌曲之后需要进行替换歌曲片段单独操作的二次创作时,可以对歌曲的某个片段进行替换操作。就可以指定如下内容:- action:内容为
replace_section。 - audio_id:之前生成歌曲的 ID。
- model: 歌曲生成模型,
- lyric: 替换后的完整歌词(只需要与 prompt 有重复就行,不需要完全的歌词),
- prompt:需要替换的歌词部分。
- style:歌曲的风格,选填。
- replace_section_start:
lyric对应的歌词时间轴的起始时间。 - replace_section_end:
lyric对应的歌词时间轴的终点时间。
声曲分离
当生成歌曲之后需要进行伴奏和人声单独操作的二次创作时,可以分离纯音乐伴奏和清唱人声。就可以指定如下内容:- action:内容为
stems。 - audio_id:之前生成歌曲的 ID。
全轨道声曲分离
当生成歌曲之后需要进行全轨道声曲分离操作时,就可以指定如下内容:- action:内容为
all_stems。 - audio_id:之前生成歌曲的 ID。
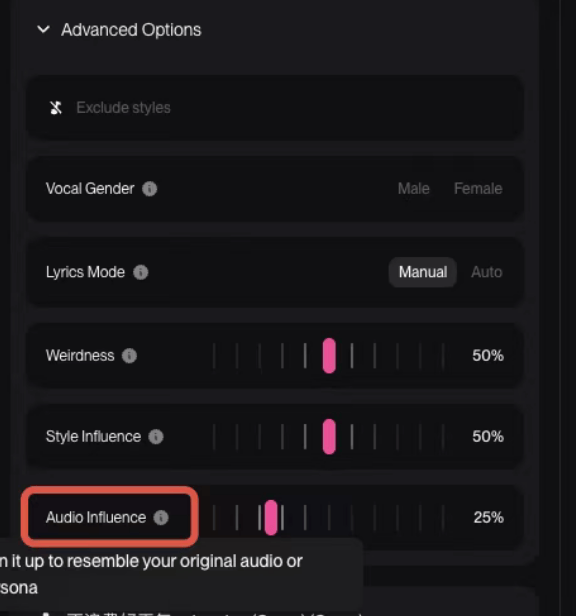
自定义生成的高级参数
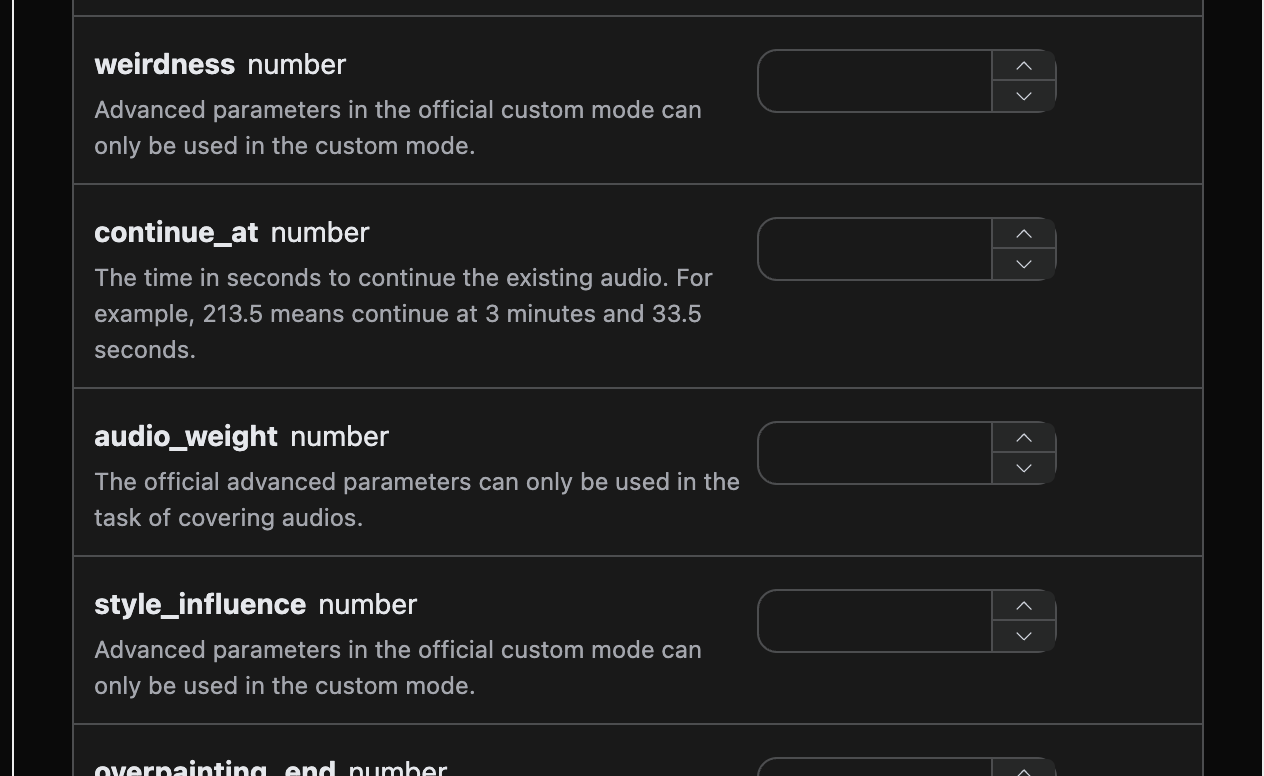
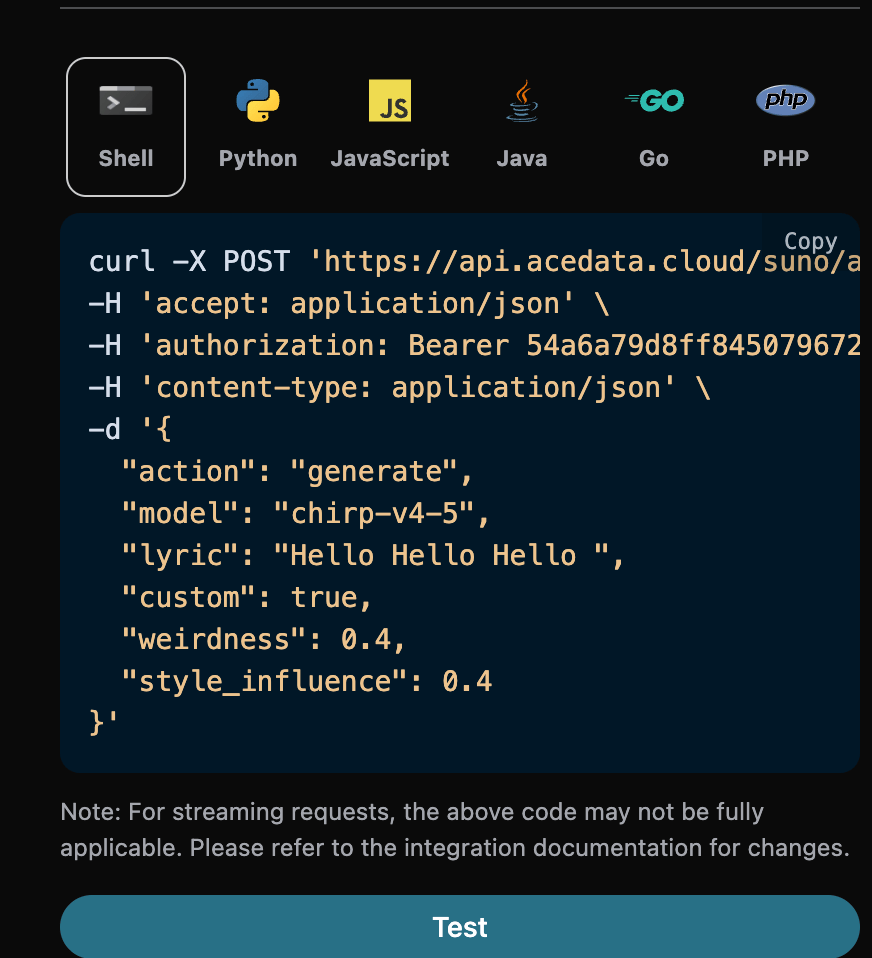
官方允许在自定义模式下使用高级参数weirdness==>Weirdness、style_influence==>Style Influence、audio_weight==>Audio Influence来进行生成,对应如下如的官方示例:
Add Insterumental 功能
2025 年 8 月份 suno 新出 Add Insterumental 功能,首先需要上传一首清唱无配音的歌曲, 让 suno 帮你配乐,首先可以先到 Suno Upload API上传一首清唱无配乐的歌曲,对应如下如的操作如下图所示: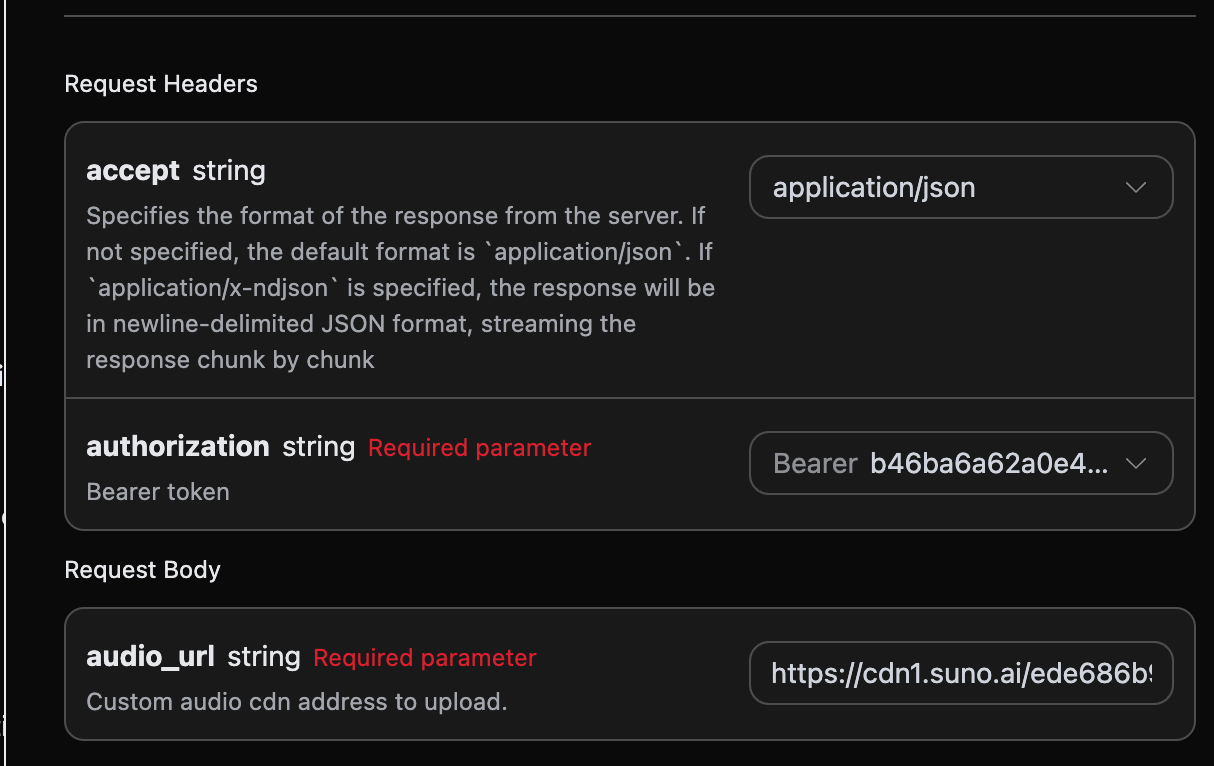
audio_id,具体的结果如下图所示:
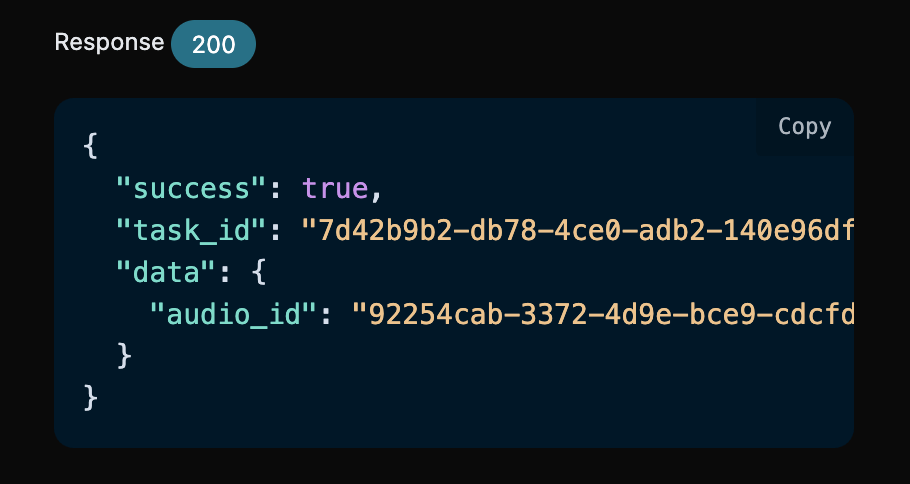
audio_id:92254cab-3372-4d9e-bce9-cdcfdbc39070,然后我们还需要填写如下参数:
- action:内容为
underpainting。 - underpainting_start:对上传的歌曲进行添加伴奏的起始时间,默认值是 0。
- underpainting_end:对上传的歌曲进行添加伴奏的终点时间,必须小于歌曲的总时长。
- audio_id:上传的清唱无配音的歌曲 ID。
- style:伴奏的风格,最好是不用歌词 毕竟是配音。
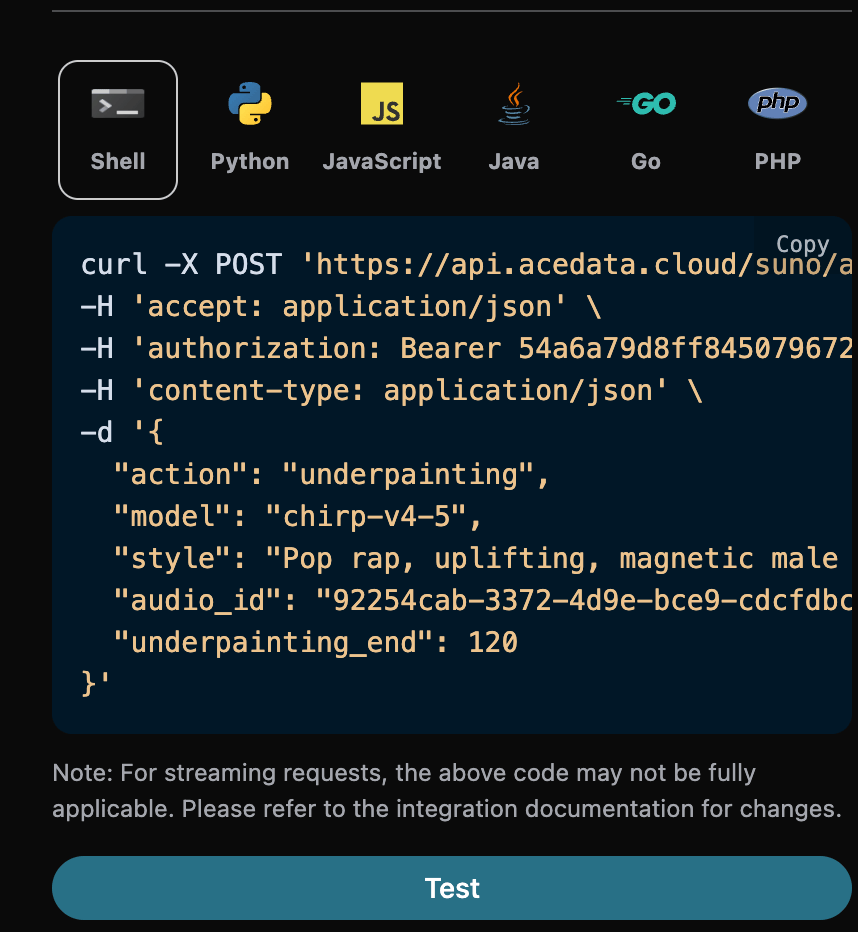
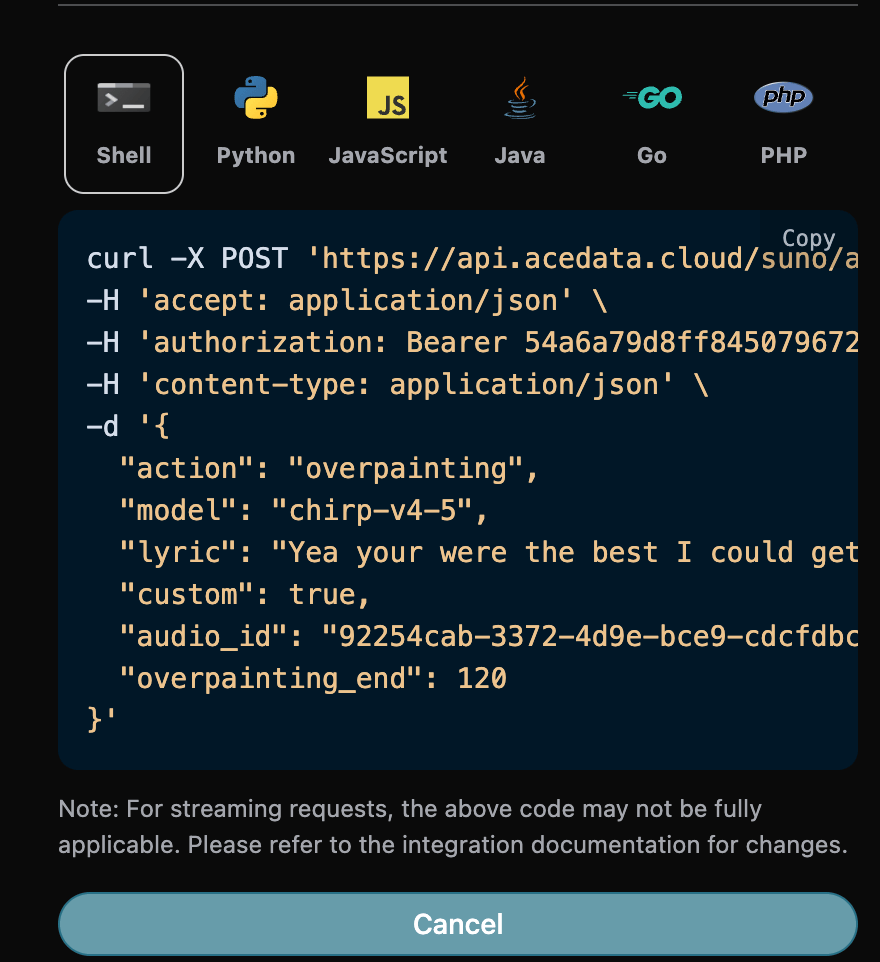
Add Vocals 功能
2025 年 8 月份 suno 新出 Add Vocals 功能,首先需要上传一首纯音乐,让 suno 填词、出人声歌唱,首先可以先到 Suno Upload API上传一首清唱无配乐的歌曲,对应如下如的操作如下图所示:
audio_id,具体的结果如下图所示:
audio_id:92254cab-3372-4d9e-bce9-cdcfdbc39070,然后我们还需要填写如下参数:
- action:内容为
overpainting。 - overpainting_start:对上传的歌曲进行添加人声的起始时间,默认值是 0。
- overpainting_end:对上传的歌曲进行添加人声的终点时间,必须小于歌曲的总时长。
- audio_id:上传的清唱无配音的歌曲 ID。
- custom:该模式下必须使用自定义模式填入歌词。
- lyric:自定义模式下填写的歌词。
- style:伴奏的风格。
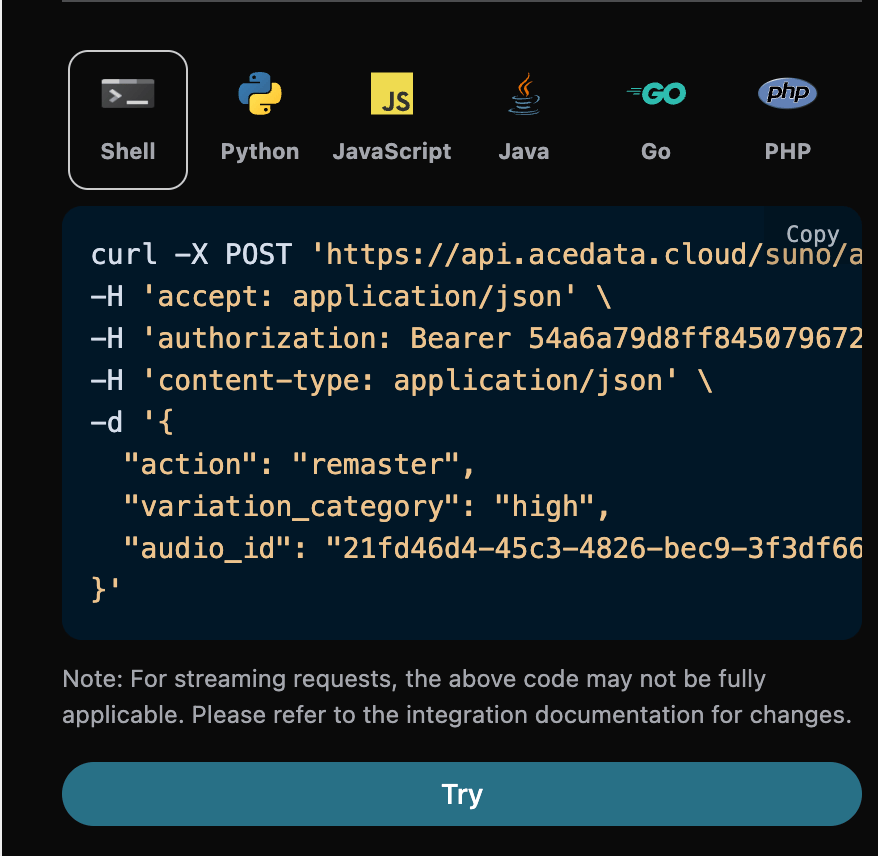
Remaster 功能
2025 年 12 月份 suno 新出 Remaster 功能,该功能可以重新生成歌曲,不可跨账号,然后我们还需要填写如下参数:- action:内容为
remaster。 - audio_id:需要重新生成的歌曲 ID。
- model:仅支持 v4.5+、v5。
- variation_category:仅在 v5 以上版本支持,而且只有 3 个值 high normal subtle。
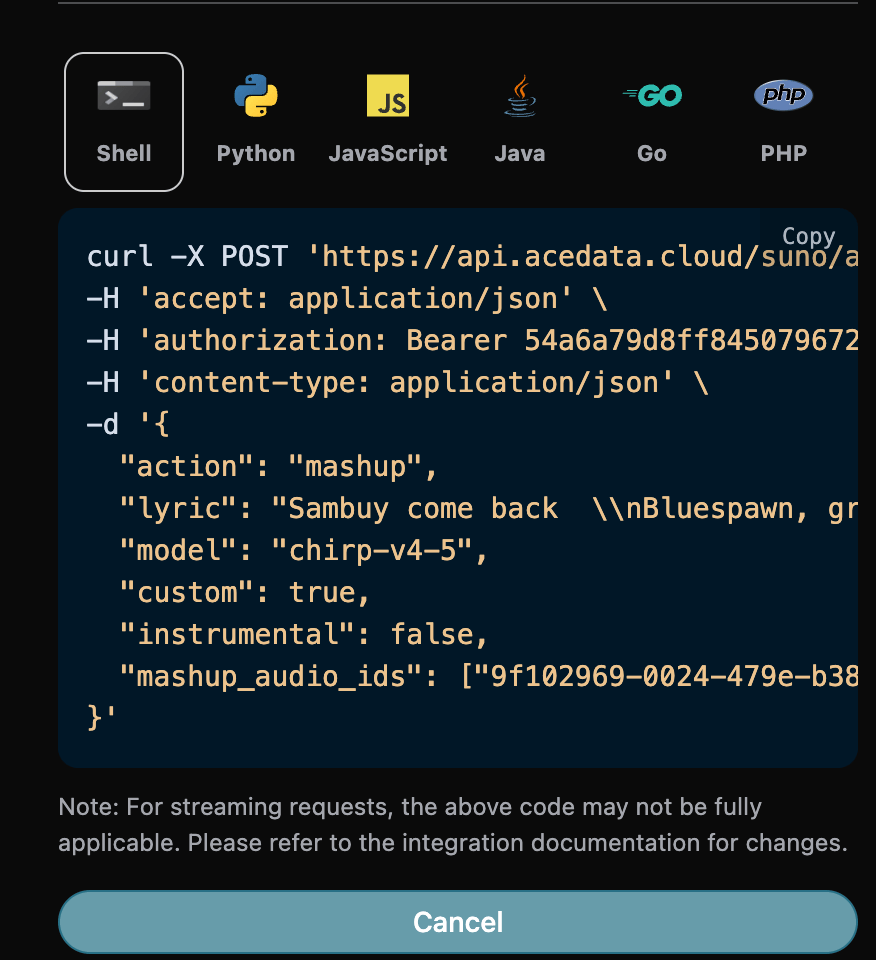
Mashup 混曲生成功能
2025 年 12 月份 suno 新出 Mashup 功能,该功能可以根据俩首参考歌曲生成歌曲,然后我们还需要填写如下参数:- action:内容为
mashup。 - mashup_audio_ids:俩首参考歌曲的 ID。
Samples 取样生成歌曲
2025 年 12 月份 suno 新出 Samples 功能,该功能可以根据俩首参考歌曲生成歌曲,然后我们还需要填写如下参数:- action:内容为
samples。 - samples_start:取样开始时间。
- samples_end:取样结束时间。
- audio_id:需要取样的参考歌曲的 ID。
异步回调
由于 Suno 生成音乐的时间相对较长,大约需要 1-2 分钟,如果 API 长时间无响应,HTTP 请求会一直保持连接,导致额外的系统资源消耗,所以本 API 也提供了异步回调的支持。 整体流程是:客户端发起请求的时候,额外指定一个callback_url 字段,客户端发起 API 请求之后,API 会立马返回一个结果,包含一个 task_id 的字段信息,代表当前的任务 ID。当任务完成之后,生成音乐的结果会通过 POST JSON 的形式发送到客户端指定的 callback_url,其中也包括了 task_id 字段,这样任务结果就可以通过 ID 关联起来了。
下面我们通过示例来了解下具体怎样操作。
首先,Webhook 回调是一个可以接收 HTTP 请求的服务,开发者应该替换为自己搭建的 HTTP 服务器的 URL。此处为了方便演示,使用一个公开的 Webhook 样例网站 https://webhook.site/,打开该网站即可得到一个 Webhook URL,如图所示:
 将此 URL 复制下来,就可以作为 Webhook 来使用,此处的样例为 https://webhook.site/03e60575-3d96-4132-b681-b713d78116e2。
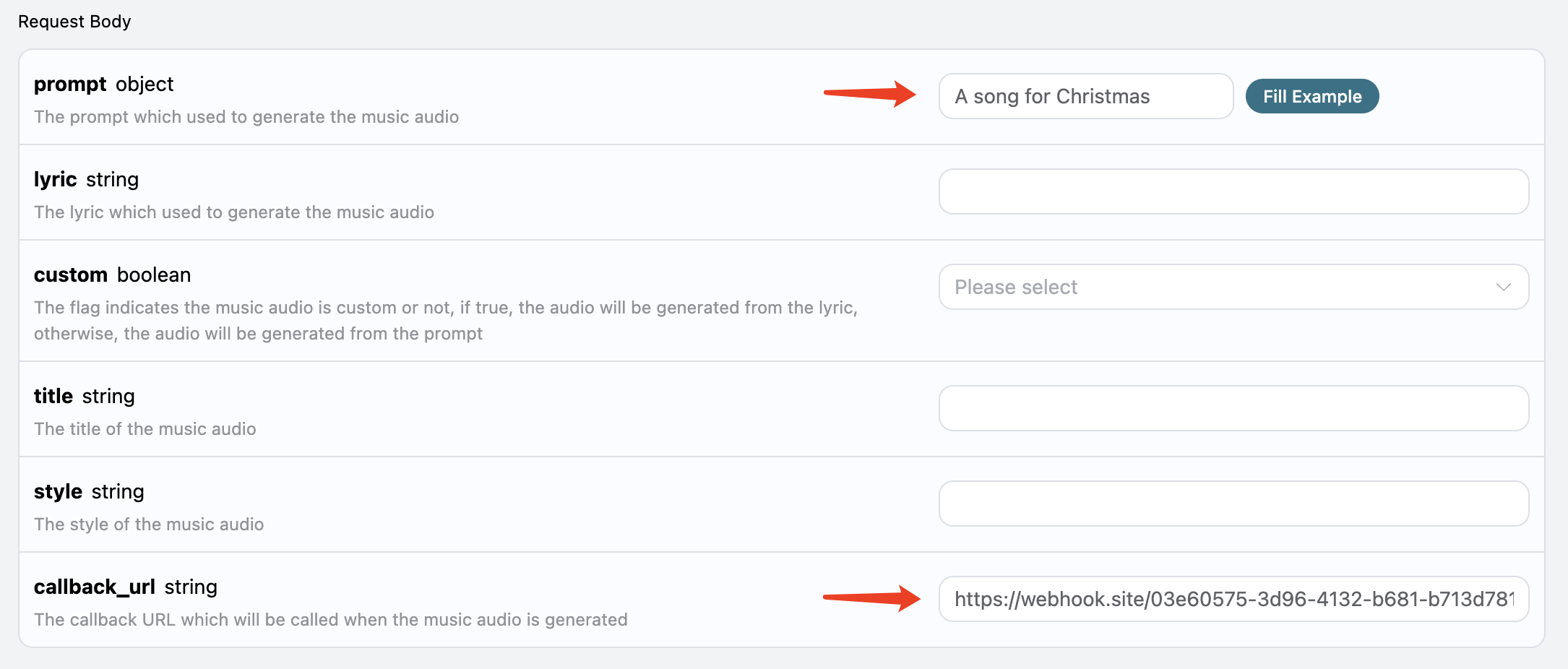
接下来,我们可以设置字段
将此 URL 复制下来,就可以作为 Webhook 来使用,此处的样例为 https://webhook.site/03e60575-3d96-4132-b681-b713d78116e2。
接下来,我们可以设置字段 callback_url 为上述 Webhook URL,同时填入 prompt,如图所示:
 点击运行,可以发现会立即得到一个结果,如下:
点击运行,可以发现会立即得到一个结果,如下:
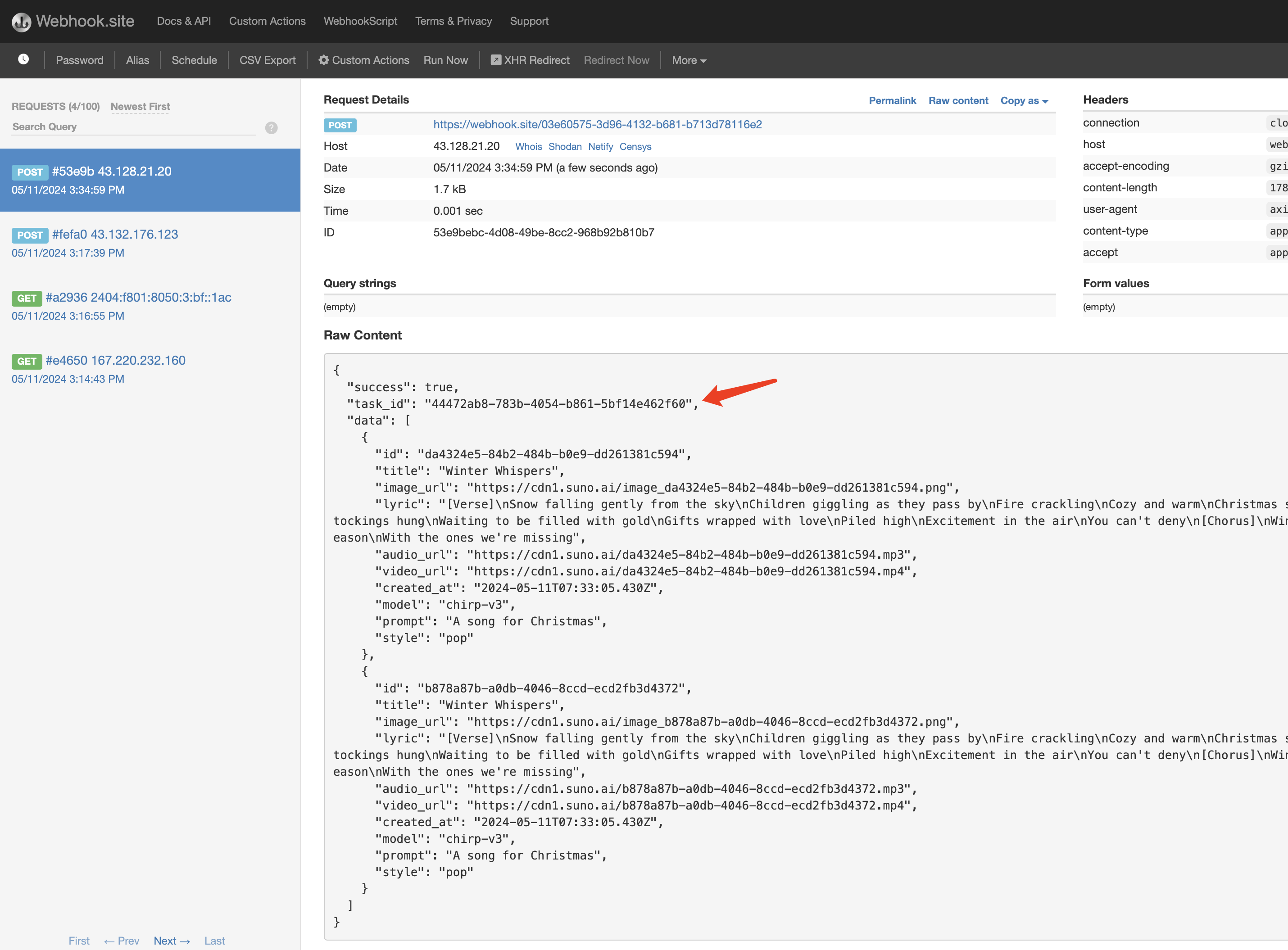 内容如下:
内容如下:
task_id 字段,其他的字段都和上文类似,通过该字段即可实现任务的关联。
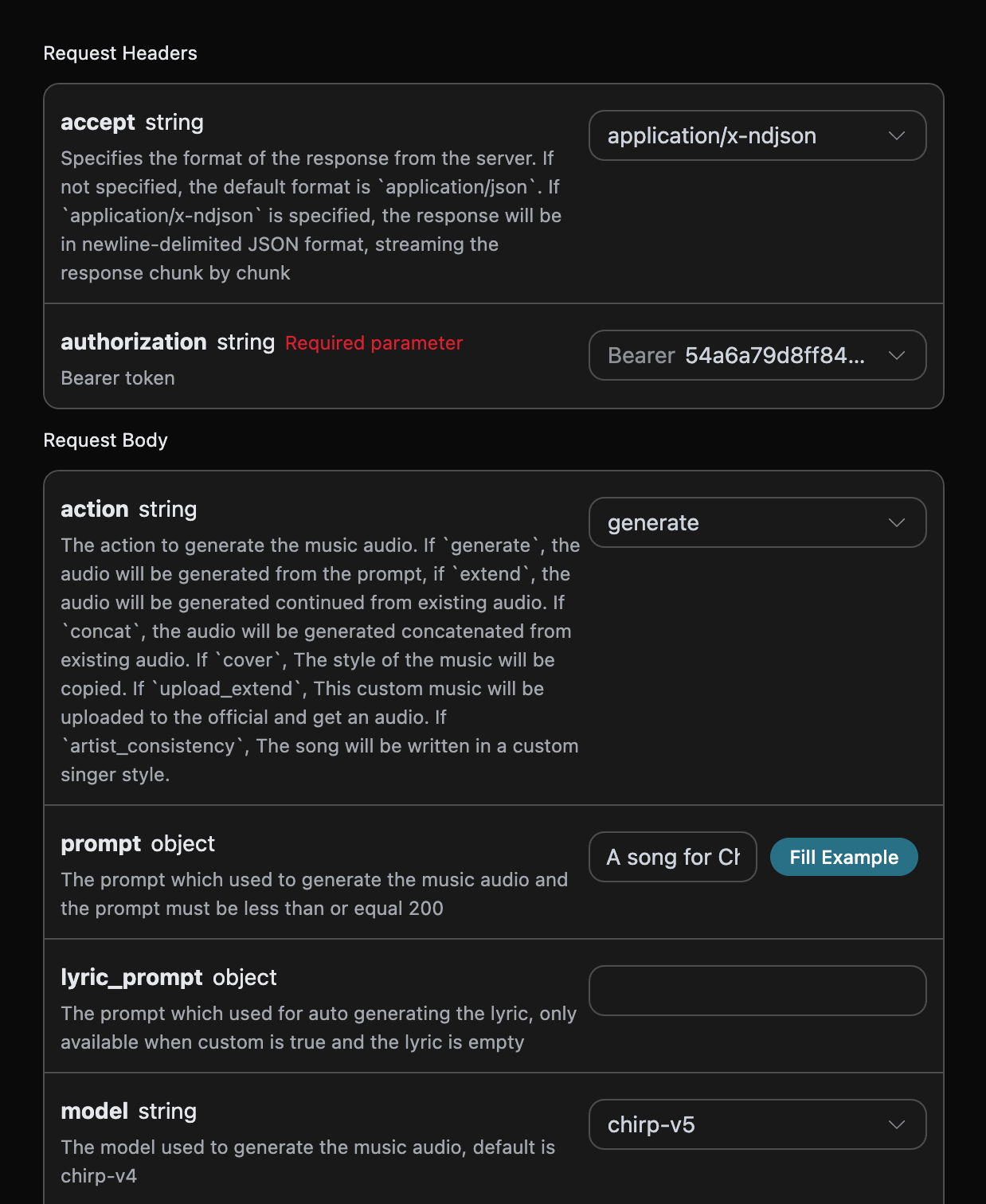
当然我们也可以通过流式调用来获取结果,我们只需要将请求头里面的accept的值设置为application/x-ndjson即可,下面用一个示例输入作为示范:
错误处理
如果发生错误,您将得到类似如下的错误信息:error.code, error.message 的列表:
| Status Code | error.code | error.message |
|---|---|---|
| 400 | bad_request | The song id does not exist or has been taken offline. |
| 400 | bad_request | Prompt too long. |
| 400 | bad_request | Tags too long. |
| 400 | bad_request | Uploaded audio matches existing work of art. |
| 400 | bad_request | instrumental must be a boolean |
| 400 | bad_request | Title too long. |
| 400 | bad_request | Topic too long. |
| 400 | bad_request | style must be less than or equal 120 |
| 400 | bad_request | custom must be a boolean |
| 400 | bad_request | audio_id is required when extend audio |
| 400 | bad_request | continue_at is required when extend audio |
| 400 | bad_request | continue_at must be a number greater than 0 |
| 400 | bad_request | lyric is required when extend audio and instrumental is false |
| 400 | bad_request | prompt is required when generate audio |
| 400 | bad_request | lyric is required when generate custom audio |
| 403 | forbidden | Prompt likely malformed |
| 403 | forbidden | Prompt likely copyrighted |
| 403 | forbidden | Prompt contained inappropriate material |
| 403 | forbidden | Song Description flagged for moderation |
| 403 | forbidden | Song Description contained artist name |
| 403 | forbidden | Tags contained artist name |
| 403 | forbidden | Lyrics contained copyrighted material |
| 403 | forbidden | Song Description contained producer tag |
| 403 | forbidden | Generic openAI error |
| 403 | forbidden | Prompt flagged for moderation |
| 500 | api_error | Unable to generate lyrics from song description |
| 500 | api_error | job failed with unknown error |
| 500 | api_error | no available worker in system |
| 500 | api_error | service under maintenance, generation paused |
| 504 | timeout | timeout while waiting for audio generation |